

Imagine that you’re responsible for determining whether the name Jesús Alfonso López Díaz matches a name on a credit report or a no-fly list. Naturally, you’d like a simple, match/no match result. After all, it seems like a straightforward matter of text comparison, so any computer should be able to perform the task.
But when it comes to entities like people’s names, things are rarely straightforward and exact matches are uncommon, no matter how powerful the computer. If this person appeared on your list with his surnames misspelled (Jesus Alfonso Lobez Deaz) or a missing surname (Jesus Alfonso Deaz), a search for an exact match would miss him.
That’s why we developed Babel Street Match to look for similarity instead of exact match, and to generate a confidence score (or “match score”) instead of a match/no match result. Many of our customers have asked how Match calculates scores, so we’ve written “Understanding Match Scoring in Babel Street Match,” a paper that explains the process. In this post, I’ll cover some of the highlights of the paper.
Why match scoring?
We’ve chosen to focus on match scoring and similarity scores in Match because we’ve seen so many business situations that require name matching. Besides trying for true positives and true negatives, decision makers must also think about false positives and false negatives.
Some uses of name matching, such as border security, tolerate more false positives. Inspectors don’t want to miss potential matches, because there is high risk in admitting a dangerous person. For other uses, such as Know Your Customer (KYC) financial onboarding or transaction linking, organizations prefer fewer false positives because the risk is lower and most mistakes can be rectified later. They want to see only the most likely matches.
So, the real value of name matching software isn’t in simply returning “match” or “no match.” The real value lies in equipping the human decision-maker for the next step in the decision process. Software like Match does that by returning matches and indicating how confident it is in the strength of the match.
That’s where scoring comes in. Since entities rarely match exactly, scoring gives an objective, consistent way to measure the likelihood, or confidence, that two names are similar. Similarity scores help automate decision-making when the names aren't an exact match.
How does Match perform match scoring? AI-powered, hybrid, two-pass.
Several approaches have evolved in using software to match names.
- Edit distance
- Rules-based: list method
- Rules-based: common key
- Statistical similarity
- Hybrid
In all approaches, the goal is to quantify the difference, compute a score, and rank results. But no single approach is ideal for all business situations.
That’s why Match is:
- AI-powered, dynamically and simultaneously considering all the ways that names can vary, not just the ways found in the list
- Hybrid, applying the strength of one approach to overcome the weakness of another
- Two-pass, using the common key method to quickly eliminate obvious non-matches and statistical similarity to intelligently score each remaining pair of names
See for yourself in Match Studio
Calculating a match score involves several steps and algorithms that we’ve optimized for performance. To make our approach transparent, we’ve developed Match Studio, with a Compare tool that lets you see the details of how Match generates scores.
The Compare tool shows you how Match uses tokens to align the different components of two names, then assigns a score based on how similar the tokens are. It then applies weights to determine the significance of each alignment. This match score computation is an example:
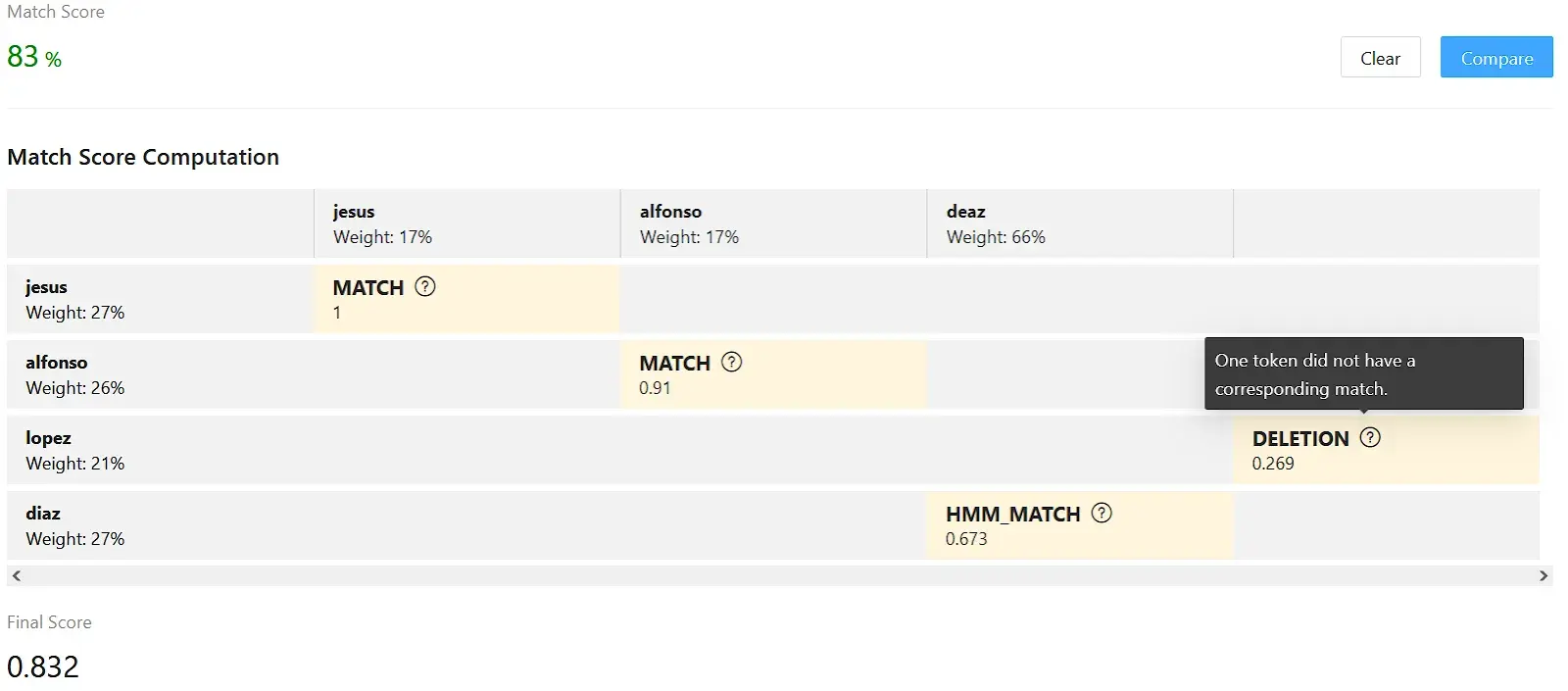
The matrix shows the decisions Match makes about the alignment of name components, the relative significance of each component, and the similarity of the components. It quantifies a deletion “penalty” because the surname López appears in one of the names but not the other. And it computes a final score of 83 percent similarity between the names.
The importance of the match threshold
So, as a decision-maker, what can you do with a match score of 83 percent?
You can easily understand the score as an indicator of probable match. Then you can convey it, either to co-workers or to software that decides how to act, given that level of similarity. They will compare it to a match threshold you have established as a business rule.
Suppose the rule dictates, “We want to reduce manual vetting as much as possible, so our threshold is 92 percent.” In that case, an 83-percent score will not be considered a match. But if the business rule dictates, “We’re willing to vet manually, so our threshold is 75 percent,” then this name will go to the next step in the decision process.
Because RMS generates a score rather than match/no match, you have the flexibility to determine the correct match threshold for your organization and then automate matching based on that. The Evaluate tool in RMS is an advanced feature designed for computing the match accuracy and corresponding match threshold of a data set you provide. With the right threshold, Match can perform AI-powered, hybrid, two-pass match scoring that is ideal for your business environment.
Your turn
To learn more about match scoring in Match, download our paper, “Understanding Match Scoring in Babel Street Match.” It differentiates Babel Street Match from the match scoring methods used in other products (in particular, Elasticsearch) and it describes how to optimize match parameters and match threshold in Match.
Also, you can go straight to the Compare tool — right now — and experiment with name matching. Compare your own name to your nickname or misspell your surname, then see how Match aligns, weighs and scores the similarity. The paper walks you through an extended example based on the name Jesús Alfonso López Díaz, and you can follow along to gauge the fit with your business situation.





